예전에 쓰레딩 빌딩 블록 설치 방법에 대해 설명을 하곤 막상 핵심을 설명을 안했네요. 이제야 올립니다. :|
오늘 설명할 내용은 tbb의 parallel_for를 이용한 병렬 프로세싱을 해볼 겁니다.
여기서 parallel_for는 우리가 아는 for문 과 비슷한 구문입니다. stl의 vector를 조금만 다뤄봤어도 그렇게 어려운 내용은 아닙니다.
먼저 다음 함수를 보도록 합시다.
|
int SerialProcess( unsigned int a[], size_t n ) {
size_t b = 100; //size_t 는 unsigned int 로 생각해도 무방합니다.
int result = 0;
for( size_t index = 0; index < n; ++index ) {
result += b + index * ( index * 2 ) + ( index / 3 - 2 ) * index;
}
return result;
}
|
간단합니다. 단순히 루프 문을 돌면서 쓸데없는 연산처리를 하죠. 우리가 아는 일반 for문을 사용합니다.
CPU가 다중 코어이고 이 작업 외엔 아무것도 하지 않는다고 가정해도 코어는 하나밖에 활용되지 않습니다.
사용법은 생략합니다. SerialProcess 를 호출하면 그만이죠.
우리는 이 구문을 parallel_for 문을 이용해서 다중 코어를 활용한 병렬 프로세싱을 하는 구문으로 바꾸도록 하겠습니다.
|
#include <tbb/task_scheduler_init.h>
#include <tbb/parallel_for.h>
#include <tbb/blocked_range.h>
using namespace tbb;
class ParallelProcessing {
public:
int return_value;
void operator()( const blocked_range< size_t >& r ) const {
size_t b = 100;
int return = 0;
for( size_t i = r.begin(); i != r.end(); ++i )
return += b + i * ( i * 2 ) + ( i / 3 - 2 ) * i << endl;
return_value = return;
}
}; |
함수를 클래스로 대체했습니다. 다른 이유는 없고 STL 스타일의 함수 객체일 뿐입니다. 중요한 내용은 operator() const 구문이고
이는 기존 함수의 역할을 하죠. 차이점이 빨간 색으로 보입니다.
그 부분의 설명에 앞서 이 함수 객체 사용과정을 보도록 합시다.
(* 참고로 const 의 연산자 오버라이딩을 하는 이유는 혹이나 있을 지 모르는 객체 복사에 의한 쓰레딩 과정의 데이터 오류를 방지하기 위해 애초에 intel사에서 객체들을 const 형으로 사용한다고 명시되어 있습니다.)
| parallel_for( blocked_range< size_t >( 0, n, 10000 ), ParellelProcessing() ); |
아이구. 사용법이 생각보다 간단합니까? parallel_for 문은 2개의 인자를 받습니다.
첫번째 : blocked_range< size_t >&
두번째 : 처리할 함수 객체
첫번째는 blocked_range< size_t > 인데 바로 루프문을 돌릴 객체가 되겠습니다.
두번째 같은 경우는 우리가 원하는 작업을 할 ParellelProcessing 객체를 호출합니다.
blocked_range는 루프문을 돌릴 형을 템플릿으로 지정하고,
|
blocked_range< size_t >& r
for( size_t i = r.begin(); i != r.end(); ++i ) { ... } |
생성자에서 세 개의 인자를 받습니다. ( 0, n 10000 )
첫번재 : 0은 루프문의 초기 위치 값입니다.
두번째 : n은 루프문의 마지막 위치 값입니다.
세번째 : 10,000은 grain_size 라고 하는데, 각 프로세서가 처리할 반복문의 합리적인 크기(범위)라고 생각하시면 됩니다.
만약 반복문의 범위가 20,000 이고 grain_size를 10,000 으로 지정한다면, 두 개의 프로세서가 각각 한 번에 일을 끝내버리겟죠.
따라서, 이 세 번째 인자값으로 인해 병렬 프로세싱의 작업량을 조절할 수가 있습니다. 만약 실제 반복문의 크기가 각 프로세서가 처리할 반복문의 범위보다 크면 parelle_for 문에서 알아서 작업량을 분할해 주기도 합니다.
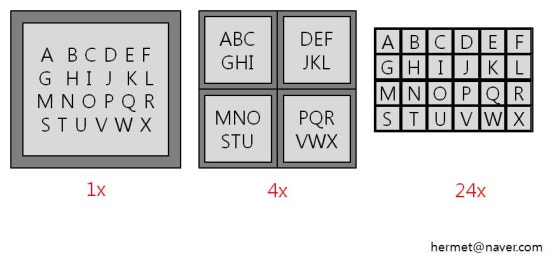
부가적으로 설명을 더 하자면, 위 그림을 보시면 맨 왼쪽의 A ~ X 까지의 네모 상자를 하나의 작업이라고 가정합니다. 이는 우리가 구현한 ParallelProcessing 함수 객체가 되겠죠. 이를 1X, 4X, 24X 와 같은 식으로 하나의 작업을 추상적으로 분열할 수가 있습니다.
문제는 하나의 작업을 너무 세밀하게 분할해 버리면 각 루프문에서의 각 작업량 생성 과정에서 오히려 작업부하를 발생시킬 수 있습니다.
grain_size . 정말 난해한 인자 입니다.
따라서, 이 값의 정답은 없으며 이는 각 프로세싱 환경에 맞게 사용자가 조절해 주어야 합니다. 이 일을 대신해 주는 auto_partitioner 라는 클래스도 존재하지만 사용자가 직접 지정해주는 것 보단 완벽하진 않습니다.
결론은, intel 사에서 제안한 방안은 다음과 같습니다. 일단 10,000 ~ 100,000 범위의 값이 적합하다고 합니다.
그리고 다음과 같은 방법으로 성능 테스트를 하라고 나옵니다.
1. 실제 필요 이상으로 grain_size 값을 설정한다. 이는 보통 10,000 이 적합하다.
2. 하나의 프로세서에서 알고리즘을 실행해 본다.
3. 값을 감소하면서 성능 체크를 한다.
4. 알고리즘 수행 시간이 5 ~ 10 퍼센트 감소하면 대체로 적합한 값이 된다.
저 같은 경우는, 단일 프로세서는 아니고, 실제로 값을 조절해 보면서 성능 테스트를 해 보았더니 30,000에서 가장 좋은 성능이 나오더군요.
결론을 드리자면, 직접 성능 체크를 하면서 적합한 값을 찾으라는 겁니다. 또한 루프문의 작업 량에 따라 오히려 단일 프로세싱이 더 빠를수도 있습니다.
참고로 아래는 auto_partitioner를 이용한 호출입니다.
| parallel_for( blocked_range< size_t >( 0, n ), ParellelProcessing(), auto_partitioner() ); |
이상 parallel_for 설명을 마치며 참고 소스 첨부합니다.
- 참고 : Intel Threading Building Blocks ( O'REILLY )-
